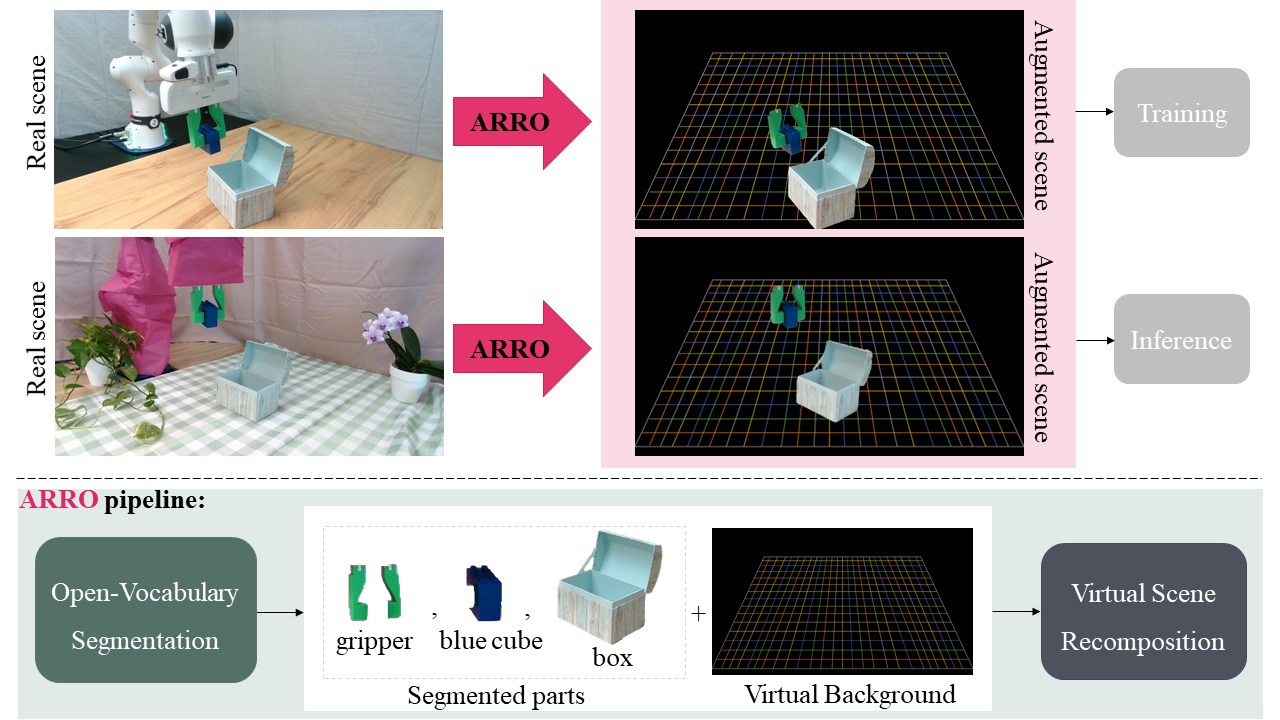
Visuomotor policies trained on human expert demonstrations have recently shown strong performance across a wide range of robotic manipulation tasks. However, these policies remain highly sensitive to domain shifts stemming from background or robot embodiment changes, which limits their generalization capabilities. In this paper, we present ARRO, a novel calibration-free visual representation that leverages zero-shot open-vocabulary segmentation and object detection models to efficiently mask out task-irrelevant regions of the scene without requiring additional training. By filtering visual distractors and overlaying virtual guides during both training and inference, ARRO improves robustness to scene variations and reduces the need for additional data collection. We extensively evaluate ARRO with Diffusion Policy on several tabletop manipulation tasks in both simulation and real-world environments, and further demonstrate its compatibility and effectiveness with generalist robot policies, such as Octo, OpenVLA, and π0. Across all settings in our evaluation, ARRO yields consistent performance gains, allows for selective masking to choose between different objects, and shows robustness even to challenging segmentation conditions.
Visuomotor policies trained through imitation learning often fail to generalize across visual domain shifts. Minor changes in background, lighting, or robot appearance at test time can lead to substantial performance drops.
In the example above, the robot learns to drop a cube into a box and close the lid. At inference, the same task is attempted in a visually altered scene, with changes in background, distractors, and robot embodiment. While standard policies break, ARRO filters out irrelevant content, retaining only the gripper, cube, and box, and overlays them on a structured virtual background. This abstraction makes ARRO robust to visual variation. To isolate the role of spatial cues, we also provide an ablation using a plain black background.
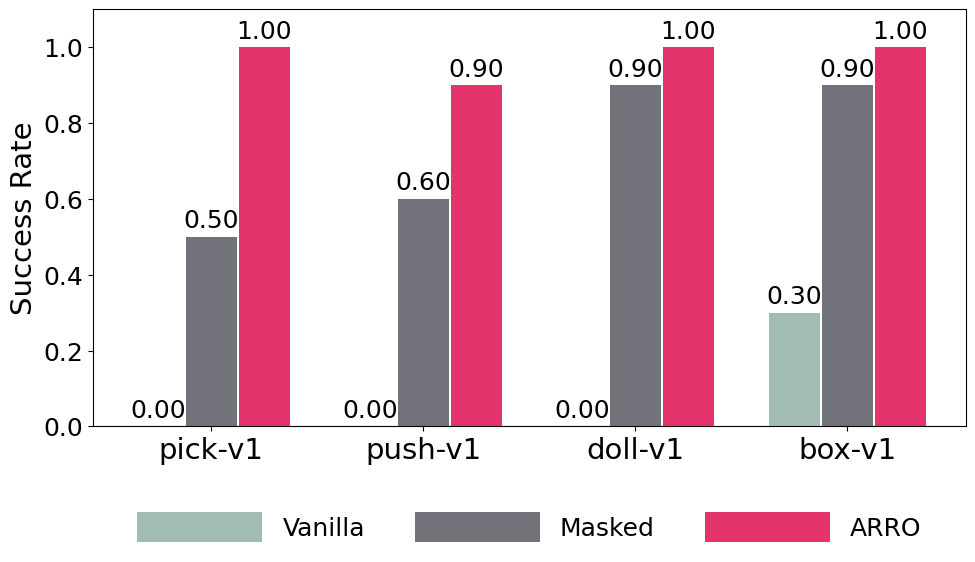
The Vanilla Diffusion Policy performs poorly under domain shifts due to its dependence on raw visual features. The Masked Diffusion Policy does better by removing distractors but still underperforms compared to ARRO, likely because it also removes useful cues. ARRO outperforms both by filtering out irrelevant information while restoring a consistent background, leading to improved robustness and generalization.
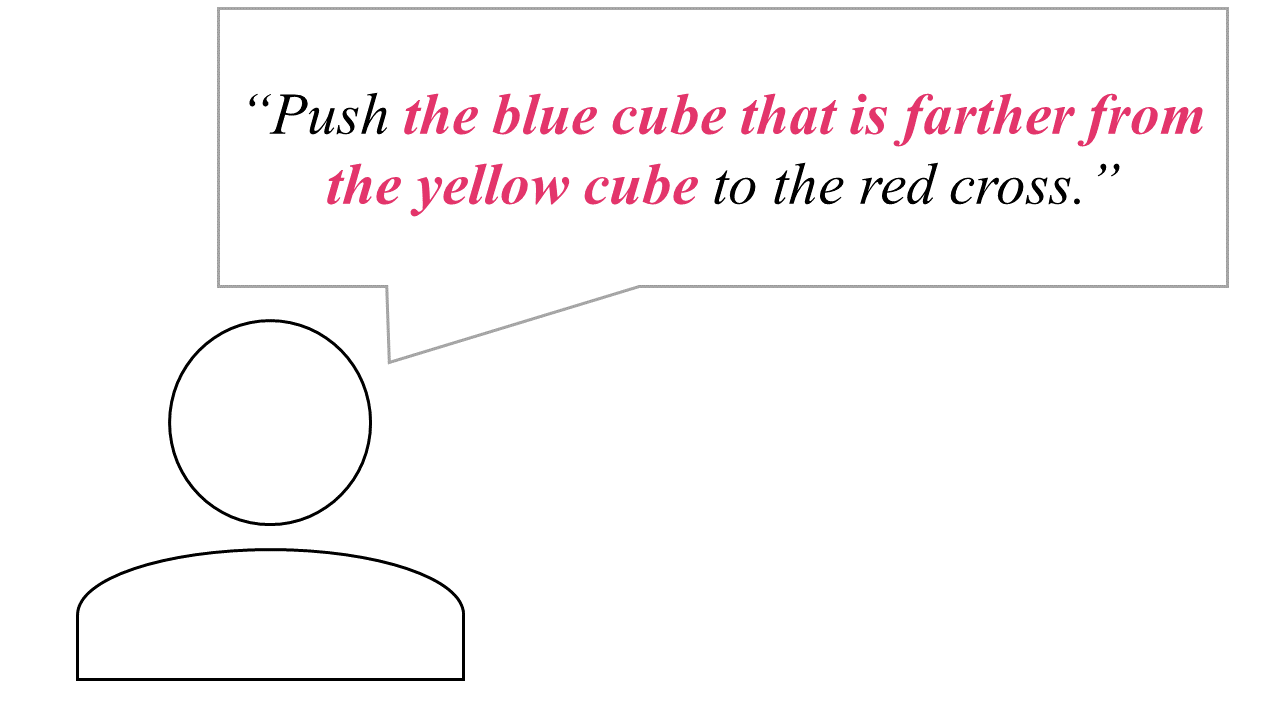
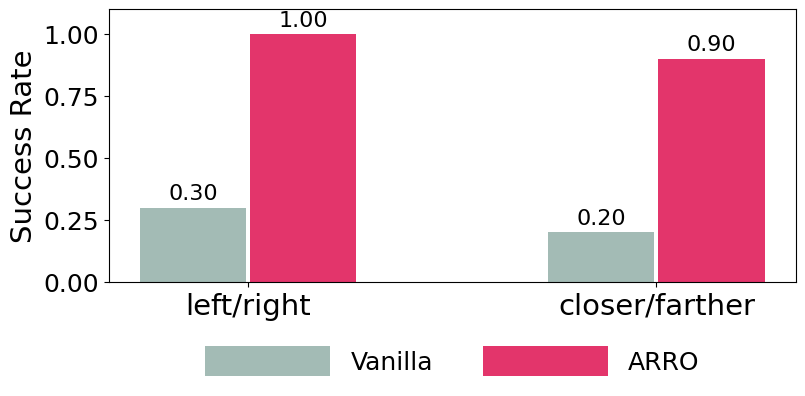
In this setup, the robot receives a natural language instruction: “Push the blue cube that is farther from the yellow cube to the red cross.” Executing this task requires spatial reasoning and grounding language in the visual scene. Standard visuomotor policies often fail when the scene layout changes or distractors are present. ARRO addresses this by abstracting away irrelevant regions and retaining only the gripper and target object. This abstraction supports robust relational reasoning. As shown above, ARRO generalizes zero-shot to new configurations, succeeding in both left/right and closer/farther variants without additional training.
In this visualization, we zoom into two visually rich tasks. Despite the presence of rich textures, non-rigid shapes, and occlusion, ARRO's segmentation module consistently identifies and preserves the task-relevant components: the gripper and manipulable objects. This robustness in visual abstraction enables generalist policies to execute precise actions even in the presence of complex, unfamiliar visual elements—without any additional training or fine-tuning.
Generalist-policy results from the paper, including π0 and the wrist-camera evaluation.
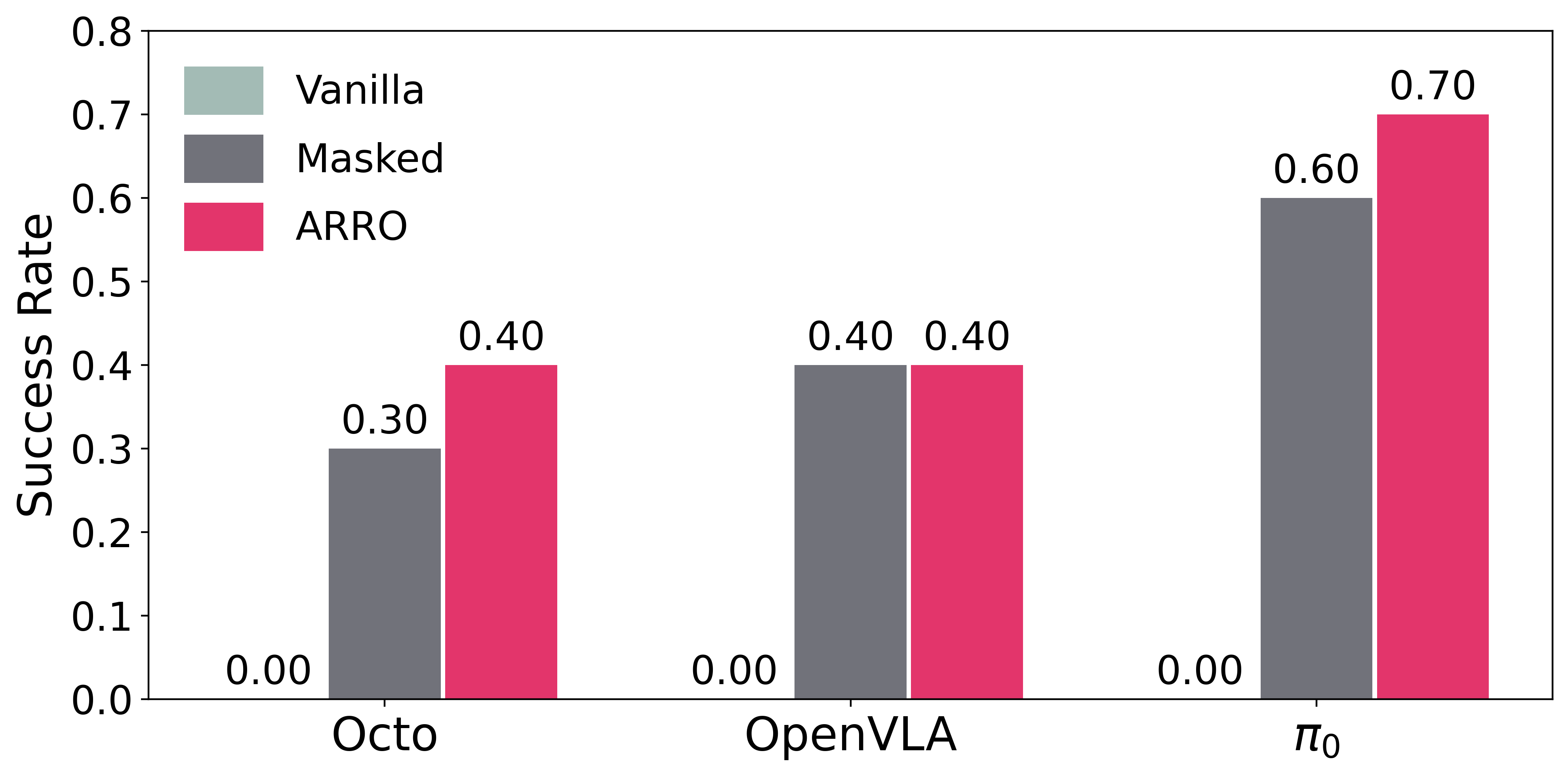
ARRO is not tied to a single policy architecture. It improves robustness not only for Diffusion Policy but also for the language-conditioned generalist models Octo, OpenVLA, and π0. For Octo and OpenVLA, the altered-scene setting still causes sharp failures for vanilla inputs, while masked and ARRO inputs recover performance. The new π0 study is especially interesting because it uses a side camera plus a wrist-mounted camera and joint-space control, extending ARRO beyond the earlier third-person-only presentation.

Cluttered wrist view. Vanilla π0 is fairly robust, so the paper adds substantially more clutter to expose failure cases.

Masked wrist view. For the wrist camera, ARRO uses a black background, while the structured ARRO pattern is applied to the side camera.

Language grounding stress test. Adding a second cuboid can make vanilla π0 ignore the requested color and grasp the wrong object.

Task-relevant filtering. ARRO removes the irrelevant cuboid so the policy sees only the intended object and gripper context.
Applying ARRO to a wrist camera requires extra care because the background changes as the arm moves and relevant objects may briefly leave the field of view. In this setup, segmentation is initialized from a pre-recorded scene image, the gripper fingers are selected directly from their fixed wrist-view start pose, and the wrist stream uses a plain black background. This lets ARRO recover strong performance on the task “pick up the green cube”, including the color-confusion setting where success rises from 30% for vanilla π0 to 70% with masking and 90% with ARRO.



Real-world FR3 setup, simulated FR3 replica, and simulated UR5e embodiment used for the transfer experiments.

For real-to-sim, Diffusion Policy, Octo, OpenVLA, and π0 are compared; for cross-embodiment, the FR3-trained policies are transferred to a UR5e in simulation. OpenVLA benefits most clearly in real-to-sim transfer, retaining 55% of its original success rate with ARRO, while Diffusion Policy jumps from 0% to 99% retained performance in the cross-embodiment experiment. The new table also makes the camera/control differences explicit: π0 uses side plus wrist cameras and joint control, and in that real-to-sim setup masking retains 94% of its original performance. No cross-embodiment result is reported there for π0.

To assess how well our ARRO policies generalize across different robotic embodiments, we trained them on the FR3 robot in simulation and evaluated their performance on a distinct UR5e embodiment. While baseline diffusion policies suffered a complete performance collapse when transferred, ARRO and masked variants demonstrated strong cross-embodiment generalization with only minor reductions in success rates. In particular, Diffusion Policy improves from 0% retained performance in the vanilla setting to 99% with ARRO, while OpenVLA rises from 29% to 80%. This robustness is attributed to ARRO’s architecture, which masks embodiment-specific features and operates in a Cartesian control space, ensuring consistent behavior across varied physical forms. These results underscore ARRO's potential for scalable deployment across heterogeneous robotic platforms.


We evaluated Diffusion Policy, Octo, OpenVLA, and π0 for real-to-sim transfer. While the side-camera models perform well in the real world, their vanilla success rates collapse in simulation. OpenVLA with ARRO and black masking significantly outperforms its vanilla version, retaining 55% of its original performance across domains, while π0 remains strong thanks to the combined side-and-wrist-camera setup and reaches 94% retained performance with masking. As shown, ARRO enables successful task execution in sim and consistently higher rewards, highlighting its effectiveness in bridging real-to-sim gaps.
@ARTICLE{arro,
author={Mirjalili, Reihaneh and J{\"u}lg, Tobias and Walter, Florian and Burgard, Wolfram},
journal={IEEE Robotics and Automation Letters},
title={Augmented Reality for RObots (ARRO): Pointing Visuomotor Policies Towards Visual Robustness},
year={2026},
volume={11},
number={4},
pages={4785-4792},
doi={10.1109/LRA.2026.3665444}}
}